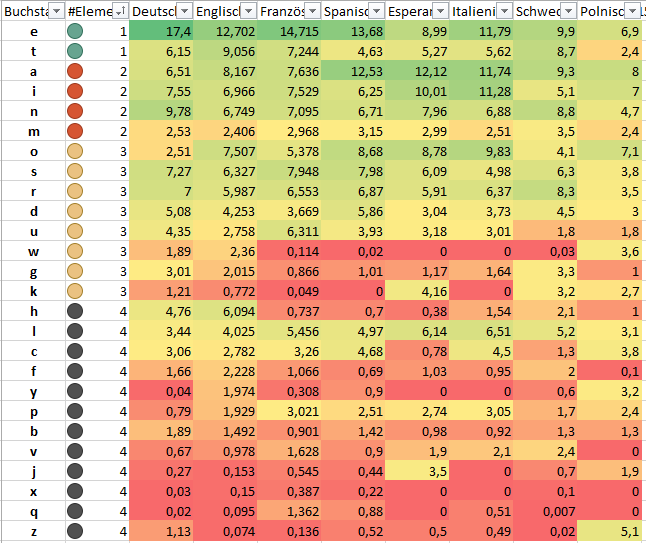
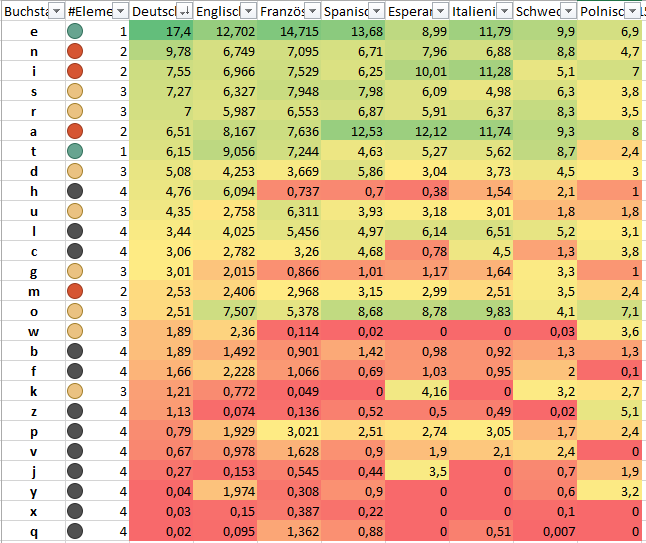
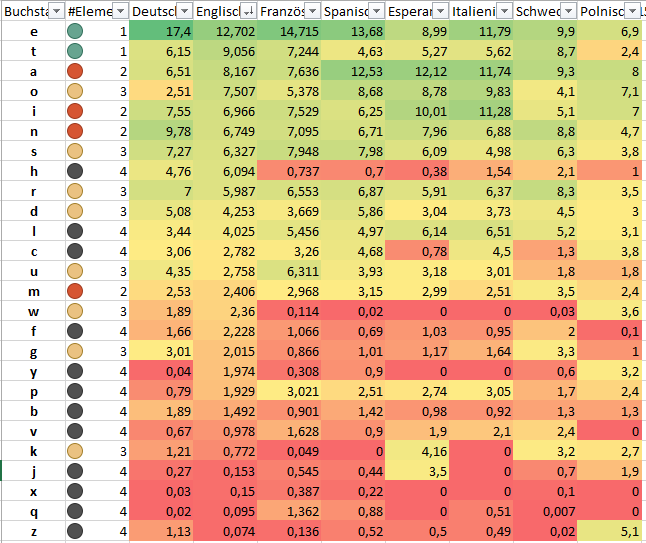
Friedrich Clemens Gerke der in Hamburg lebte, definierte
1848 eine Buchstaben Tabelle die in weiterer Folge
als internationaler Morsecode bekannt geworden und von der ITU
so genormt wurde.
Manche Quellen berichten, daß Gerke in Druckereinen nachgefragt
haben soll wie viele Stück Lettern diese zum Setzen von Texten
verbrauchen. Aufgrund dieser Verteilung soll er seine Anordnung
entwickelt haben. Hier stünde dann Deutsch als Pate, stimmt das?
Vor allem in US und UK Quellen wird immer betont das Englische
sei Quelle für die Ermittlung der Häufigkeit sei. Für die 26
Kernbuchstaben in der
lateinischen Schrift reichen 4 Elemente, also Punke und Striche
aus. Es stehen
12+22+32+42 = 2+4+8+16
also 30 Zeichen in dieser Codierung
zur Verfügung. Interessant ist daß die deutschen Umlaute
ä, ö, ü als auch das "ch" die
nach der Nutzung durch die 26 Buchstaben verbrauchen 4 übrig
gebliebenen Zeichen in dem 30'er Zeichenraum von 4 Elementen
nutzen. Also doch eher Deutsch als Sprachenparte? Alle anderen
Sonderzeichen die man in diversen Sprachen braucht haben 5
Elemente. Somit haben ä, ö, ü mit ihrer Verwendung
in Deutsch eine besodere Stellung.
Friedrich Clemens Gerke who lived in Hamburg defined 1848 a
table which later became the international morse code. It was
also normed by the ITU. Some sources report that Gerke went to
print shops to ask for the number of individual letters they use
to set the pages. According to the volumes he defined the code
set. If that is true German would be the source of the way the
code is defined. Especially US and UK sources claim that English
is the defining language for the code distribution. For the
characters of the Latin script 4 elements are enough to cover
them. But there is room for 30 of them
12+22+32+42 = 2+4+8+16.
It is quite
remarkable that the remaining 4 characters with 4 elements are
used for the German Umlauts ä, ö, ü and "ch". So
could that mean it is German??? Other languages requre a 5 element
coding for their special characters. This describes a special treatment
for the german ä, ö, ü umlaut characters.